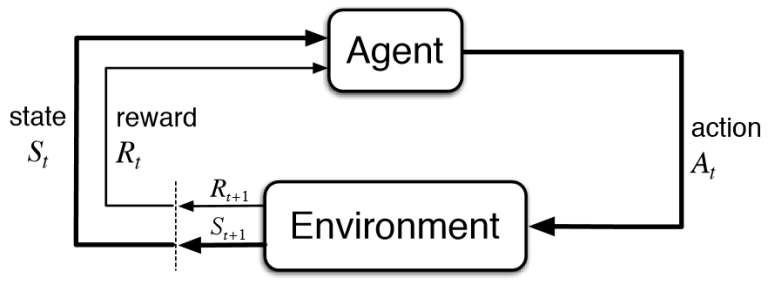
Il Reinforcement Learnig (RL) o “Apprendimento per Rinforzo” è una famiglia di algoritmi di Intelligenza Artificiale che, immersi in un ambiente, prendono decisioni per massimizzare la somma delle ricompense (reward) nel tempo. Per fare un esempio pratico, il RL potrebbe indicare ad un giocatore di slot-machine (dette in gergo armed-bandit) la migliore strategia su come e quanto spendere per provare diverse slot e quanto invece puntare su quelle più promettenti. Da qui si intuisce che una particolarità di questi algoritmi è la ricerca del miglior equilibrio fra esplorazione di situazioni sconosciute e sfruttamento della conoscenza fino a quel momento accumulata attraverso prove ed errori.
Il RL si ispira al comportamento umano in cui i neonati crescono esplorando il mondo circostante, elaborando via via una maggiore abilità attraverso una modalità che potremmo definire dal basso verso l’alto (bottom-up), cui si affianca gradualmente un modello mentale dei meccanismi profondi del mondo in cui sono immersi, con una procedura dall’alto verso il basso (top-down). L’ancora misteriosa fusione tra questi due approcci è molto potente ed è quanto si cerca di replicare nel RL.
Il RL è un’area del Machine Learning (ML) che si affianca ai più noti approcci “Supervised e Unsupervised Learning”. Nel primo, degli umani indicano il risultato corretto di un certo numero di esempi da fornire agli algoritmi per l’apprendimento e la successiva misurazione dell’efficacia (come ad esempio riconoscere sesso ed età di una persona dalla sua faccia). Nel secondo invece gli algoritmi cercano da soli il risultato ottimale senza indicazioni esterne (come ad esempio il raggruppamento dei clienti con i relativi dati di acquisto, in poche classi omogenee). A differenza di quest’ultima famiglia, gli algoritmi di RL, pur nella loro sostanziale autonomia, devono poter osservare il successo delle loro scelte e la fase di apprendimento può essere velocizzata con degli “aiuti” esterni.
Origini e stato dell’arte
Tra le origini matematiche del Reinforcement Learning si trova il Markov Decision Process (MDP), ma per le problematiche più complesse da alcuni anni sono entrate in gioco le Reti Neurali Profonde (Deep Neural Network) con diverse varianti, tra cui le Deep Q-network (DQN) alla base dei successi della giovane azienda Deep Mind di Londra, presto acquisita da Google. Con le prime applicazioni dei DQN sono stati superati i livelli umani in molti videogiochi, tra cui Montezuma Revenge del vecchio Atari 2600, spesso utilizzati dai ricercatori come punto di riferimento per confrontare i diversi filoni di sviluppo.
Successivamente nel 2016-2017 le eclatanti vittorie dell’algoritmo AlphaGO di Deep Mind su diversi campioni mondia
li di Go, un gioco orientale ben più complesso degli scacchi, sembrano aver addirittura “svegliato” il governo Cinese, che fino a quel momento non aveva dato eccessiva importanza economica e strategica all’IA. Un risveglio simile a quello degli USA quando nel 1957 appresero che l’URSS aveva inviato nello spazio lo Sputnik, il primo satellite artificiale.
Uno dei problemi che limita ancora l’applicazione del RL in ambito aziendale è l’elevato numero di interazioni con l’ambiente per arrivare a buoni risultati, tanto che a volte vengono addirittura creati degli algoritmi per allenare altri algoritmi con le Generative Adversarial Networks (GANs).
Un’altra differenza del RL rispetto ad altre forme di IA è che, specialmente nelle più moderne varianti come le DQN, possono operare sulla più ampia gamma di problemi tanto da parlare di percorso verso l’Intelligenza Artificiale Generale, cui si potranno fornire enormi quantità di dati digitali (libri, trattati, immagini, filmati, log di sensori …) per sintetizzare automaticamente conoscenza e comprensione del nostro mondo.
Perché il Reinforcement Learning è importante nel Retail
Nelle catene di negozi è utile ottimizzare assortimento, disponibilità e prezzi in modo diverso regione per regione o, ancora meglio, negozio per negozio, e soprattutto è vitale adeguarsi costantemente all’evoluzione degli stili di vita, agli effetti delle comunicazioni commerciali proprie, dei produttori e dei concorrenti locali. Mentre per molte famiglie di algoritmi di IA il processo di apprendimento dovrebbe essere ripetuto periodicamente ed il modello rimarrebbe immutato fino alla successiva rielaborazione, il RL persegue naturalmente l’ottimizzazione continua degli obiettivi in un ambiente in evoluzione. Inoltre Google ha introdotto nel 2017 il concetto di Federated Learning in cui si demanda alla periferia (edge) il compito di imparare dall’attività quotidiana modificando immediatamente il proprio comportamento, pur condividendo appena possibile la conoscenza locale con il centro e gli altri nodi periferici.
Un approccio non naturale per altre famiglie di algoritmi consiste nel sacrificare a volte gli obiettivi a breve termine, come invece riesce a fare il RL. Per fidelizzare un cliente e massimizzare l’utile sul lungo termine, a volte si devono affrontare investimenti iniziali.
Quando si introduce una nuova promozione, non esistono dati per capire le migliori correlazioni con i diversi tipi di cliente e di spesa. Fortunatamente il RL inizia subito a prendere decisioni, a volte di natura “esplorativa”, e comunque a migliorale giorno dopo giorno.
Data la natura “Generale” di questa famiglia di algoritmi, i campi di applicazione nel Retail sono pressoché infiniti e possono abbracciare l’intera supply chain, non solo per il suo efficientamento, ma anche in ottica di Economia Circolare e quindi di riduzione del consumo di risorse.
Credo che la potenza di questa famiglia di algoritmi sia evidente e con essa la necessaria e massima attenzione a non farsi prendere la mano invadendo la privacy dei clienti, come giustamente impone il recente GDPR (General Data Protection Regulation), in cui l’Europa sta facendo da apripista nel mondo.
35010 Vigonza (PD)
P.IVA/C.F: 02110950264
REA 458897 C.S. 50.000,00 €
Il software
© Copyright 2023 aKite srl – Privacy policy | Cookie policy