Immaginate il giorno in cui i dirigenti di una catena di negozi si potranno concentrare sul posizionamento di mercato, su quali esperienze offrire ai clienti per distinguersi dalla concorrenza, su come motivare il personale nei negozi a perseguire gli obiettivi qualitativi e quantitativi ed altro ancora. Le decisioni quotidiane sui prodotti da far arrivare nei negozi, in che quantità e in che preciso momento, oppure quali prezzi fissare, saranno infatti assunte da un sistema intelligente. Fantascienza?
L’era dei Sistemi Autonomi di grande complessità, in grado di ottimizzare la gestione anche in presenza di fatti anomali, è più vicina di quanto si pensi, come testimonia Project Bonsai for autonomous systems – Microsoft AI, frutto dell’acquisizione della omonima startup nel 2018, attualmente in fase di test pubblico.
Dal Supervised al Reinforcement Learning
In un sistema aziendale complesso, la fase del tradizionale Machine Learning (ML) consisterebbe nell’analisi, da parte di esperti del settore, di migliaia di situazioni diverse e nella definizione, per ognuna di queste, delle decisioni ritenute ottimali. Questi esempi, elaborati da un sistema di ML, consentono di creare un “cervello” (un modello della realtà con cui prendere decisioni in una situazione futura). Tale approccio tuttavia non può funzionare in pratica, non solo per l’enorme sforzo di annotazione di casi reali che oltretutto si potrebbe rivelare viziato da abitudini radicate, pregiudizi, interessi personali … ma anche perché il mercato cambia troppo rapidamente.
Una strategia migliore è quella di cui ho parlato in aKite – Il Reinforcement Learning nel Retail. Si definiscono gli obiettivi e si lascia al sistema la ricerca dell’algoritmo più adatto e la sua ottimizzazione attraverso una continua esplorazione di diverse alternative, alla ricerca di quelle più efficaci. Una sorta di evoluzione Darwiniana, basata su algoritmi frutto di decenni di ricerca scientifica.
Il Reinforcement Learning ha il vantaggio di lasciare alle persone le decisioni sulla strategia a medio termine (come ad esempio massimizzazione del margine o della quota di mercato, livello di servizio desiderato …) mentre quelle quotidiane vengono prese da algoritmi che si adeguano automaticamente alle variazioni di mercato.
Questo approccio è adatto a problemi relativamente semplici, come la scelta della migliore promozione da suggerire ad ogni cliente, ma purtroppo non ad ambiti molto complessi e soggetti ad interessi contrastanti, come ad esempio le supply chain. Vediamo perché.
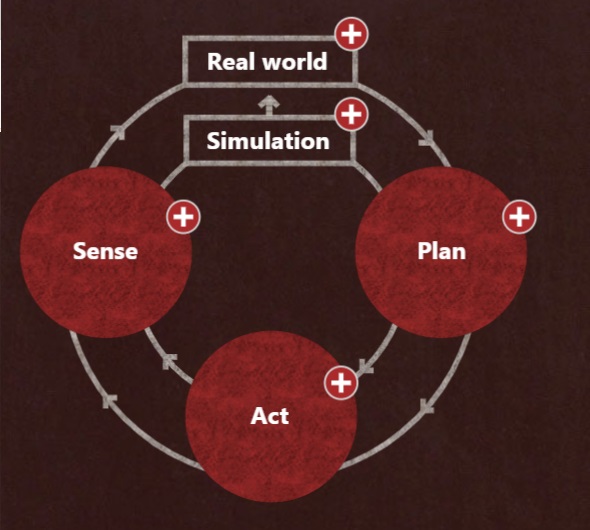
Sistemi autonomi complessi
Anche nel Reinforcement Learning (RL), la risposta di fronte alla complessità sono le Reti Neurali Profonde (DNN da Deep Neural Network), algoritmi ispirati al funzionamento del nostro cervello che hanno permesso, ad esempio, di superare l’uomo nel riconoscimento delle immagini e del parlato. Il problema è l’elevatissimo numero di “prove ed errore” da effettuare prima di arrivare a risultati soddisfacenti, tanto che gli scienziati spesso cercano di migliorare i loro algoritmi facendoli gareggiare ininterrottamente contro dei videogiochi.
Come dicevo un paio di anni fa nell’articolo citato “.. Il RL si ispira al comportamento umano in cui i neonati crescono esplorando il mondo circostante, elaborando via via una maggiore abilità attraverso una modalità che potremmo definire dal basso verso l’alto (bottom-up), cui si affianca gradualmente un modello mentale dei meccanismi profondi del mondo in cui sono immersi, con una procedura dall’alto verso il basso (top-down). L’ancora misteriosa fusione tra questi due approcci è molto potente ed è quanto si cerca di replicare nel RL.”
Nelle aziende il tempo è denaro e gli errori possono essere fatali. La novità sta quindi nella possibilità di infondere nelle DNN alcune semplici regole, vincoli e limiti da non superare, con l’ulteriore vantaggio della “spiegabilità” di algoritmi per loro natura impenetrabili (black-box), migliorando sicurezza e conformità a leggi e regolamenti che stanno nascendo, specialmente in Europa.
Nel progetto Bonsai di Microsoft, questo insegnamento Top-down tramite semplici istruzioni in un linguaggio denominato Inkling da parte di esperti del settore aziendale, non necessariamente programmatori, ha anche altri vantaggi, come il riportare parte del controllo nelle mani del business e di velocizzare enormemente il processo di apprendimento. E’ come condurre un robot, istruito per trovare la cima più alta tramite esplorazioni cieche del territorio circostante, direttamente nella catena ritenuta più promettente, evitandogli lo sforzo di esplorare un intero continente.
Altri passi avanti sono la possibilità di far funzionare questi algoritmi in parallelo alle decisioni umane, in modo che possano apprendere “guardando” come fanno gli esperti, prima di “guidare” da soli e inoltre di valutare l’efficacia di diverse strategie decisionali su un grande numero di mondi virtuali paralleli.
Conclusione
Questo è un esempio di come i progressi dell’Intelligenza Artificiale possano recare benefici alla sostenibilità aziendale e ambientale. Produrre e far viaggiare, attraverso innumerevoli micro-decisioni giornaliere, solo la merce che con buona probabilità verrà effettivamente venduta, determinerà benefici impatti sul pianeta.
35010 Vigonza (PD)
P.IVA/C.F: 02110950264
REA 458897 C.S. 50.000,00 €
Il software
© Copyright 2023 aKite srl – Privacy policy | Cookie policy